
Directory Structure
The public component of a website is a repository for information files which are delivered to the client on demand. The better organized the information is, the easier the site will be to build, manage and maintain. The key to organization is a meaningful system for filing information.
- Dogs
- Abby
- Boxer
- Chester
- Cats
- Izzy
- Jack
- Lulu
- And within the “dogs” and “cats” categories are individual animals indicated by name
- Other small mammals is another broad category that contains these subcategories:
- Guinea Pigs
- Helen
- Humberto
- Hamsters
- Tank
- Tiny
- Rabbits
- Bonbom
- Peaches
- Suzi
- And within each of these subcategories are individual animals indicated by name
- Guinea Pigs
Directory Structure
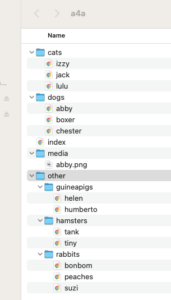
Sample Website Directory Structore for Animals for Adoption
A tiered website directory structure, like the hypothetical one in the diagram, can be displayed as if it were an organizational chart because files are stored in hierarchically arranged directories. What is not intuitively obvious about hierarchical directory structures is that lower level directories are contained entirely within the upper level directories.
In the example there are only these directories are at the root level:
dogs, cats, other, media
All subordinate directories and files are completely contained within these root directories.
In this example the entire website “Animals for Adoption” is contained within the root (topmost) directory or “a4a”. A website home page generally resides in the root directory. Lower level web pages, which generally comprise the bulk of the content of a website, reside within the appropriate subdirectories:
File Paths
The route that must be taken down through a hierarchical directory structure to locate a file within a subordinate directory is called a path. An analogy might be useful to demonstrate the concept of a path.
If you were in the front foyer (root level) of your house and wanted to get a snack on the second shelf of the refrigerator in the kitchen, the path to the snack might be diagrammed like this:
foyer > kitchen > refrigerator > second shelf > snack
or, in computer language: /foyer/kitchen/refrigerator/second shelf/snack/
Extending this simple logic, in the example website directory structure shown in the diagram, suppose that there was a media file named abby.png stored in directory “media”. 
abby.png – image of Abby – Dog Available for Adoption
The full path to this file would be: /a4a/media/abby.png
Note that spaces, special characters and capitalization count and must match exactly!
Almost all file paths are case, character and place sensitive, especially on the Internet. This is common in the Unix/Linux systems which pervade the Internet.
Note also that the directory names are separated by a forward slash / rather than the back slash.
When the ultimate target of a path is, itself, a directory rather than a file is preferable. As in the example above, it is good form to end the path with a forward slash, as well.
Proper paths to the content of a website are critical because they are lead to the uniform resource locators (URLs) that are used to point users to the right site/pages. URLs which contain incorrect path information are often referred to as broken or malformed and will lead users into dead ends and the dreaded HTTP 404 error:
The HTTP 404 error, also known as ‘404 Not Found’, is a standard response code indicating that your browser reached the server, but the requested resource couldn’t be located. It’s often caused by issues with DNS settings, improperly set file permissions, or a problems with the directory structure.

Key Takeaway
The Critical Nature of Planning in Web Design
Most novice web authors make the mistake of allowing their websites to grow by adding page after page without giving thought to sequence, meaning and consistency. They add more and HTML documents as their site grows. They often make the mistake of placing all the HTML documents and files that support them in a single root level directory in a number of files with names that are not particularly meaningful. As time goes by the content of this directory becomes more complex, unorganized, less meaningful and challenging to manage, i.e. chaos!
It is far better to organize the site from the outset into a clear directory structure which can accommodate all the content logically. Start by developing an outline of the prospective site content and mirror this in the directory structure.
In the examples of website structure shown here (Acceptable) it places all the content in a single root level directory and uses meaningful file names for constituent HTML documents. That is OK for small and uncomplicated websites, but for larger, more complex websites it quickly becomes inadequate and makes maintenance and management more difficult. In the “Better” structure, there are directories for each category of information within the website. This does not require that HTML documents receive mnemonic (meaningful) names because each is contained within its own directory.
Acceptable: (for small websites)
/animalsforadoption.org (root directory)
dogs.html
index.html (home page)
cats.html
other.html
Content of the site resides entirely within the root directory. Content is managed by giving mnemonic names to HTML documents which contain various components of the website. This makes URLs to the content less obvious and makes the organization of the site difficult for a user to follow.
Better:
/animalsforadoption.org
index.html (main home page)
/dogs
index.html (home page for dogs)
/cats
index.html (home page for cats)
/other
index.html (home page for other small mammals)
Content of the site resides in a directory structure which mirrors the structure of the information. Content is managed by segregating it into a sensible directory structure. This makes URLs to the content plain and the organization of the site easier for users to follow.
File Naming Conventions
There are index or default HTML document file names defined on most servers, including the one we use for this course.
Generally, the file names index.html and index.htm are default names which will load automatically when an URL points to a directory name rather than a discrete file. Using the default file names makes URLs to the content on a website more intelligible to the user and easier to remember. Additionally, the default index file intercepts any user who enters the directory and forces display of the content it contains.
In the “Acceptable” example above, note that the default index file name is used in every directory of the website. This means that URLs which address the content need only reference the directory in which information resides.
Shown below are the URLs which would be required to address information on the websites in the examples above:
Acceptable: http://www.animalsforadoption.org/dogs.html
Better: http://www.animalsforadoption.org/dogs/
One of the challenges novice web authors have is understanding index files and how they work. How is it that multiple files can have the same name but different content if they reside within different directories on a website?
An analogy might be helpful. Consider how many people with the last name “Reyes” may live in your neighborhood. They all share the same name but you have no difficulty in telling one Reyes from another. Why? Because they all look different (have different content) and live in different houses (directories). So what’s the problem with index files all bearing the same name – index.html – but having different content and residing in different directories on your site? There is no problem as long as the files, folders and directories stay organized!
Now, let’s get real...we are going to begin creating our first web page and transferring it from our local computer to the server which will then display on the world wide wide when called by a browser with a functional URL (uniform resource locator).

A web designer (you) create (.html) files/documents on your local computer (recommended code editor: Visual Studio Code)

Then you’ll use a file transfer protocol (FTP – recommended: FileZilla) to move the files to our HCC server –
hccwebdev.net. The server is named as such because it “serves up” web pages to the user who calls for them by a uniform resource locator (URL)

Once the files have been transferred, you will determine and test the URL (use a separate browser or send it to your phone) to ensure it is functional, meaning that it does indeed navigates to your webpage. (Browser recommended for testing: DuckDuckGo). Then a user (usually me!) uses the URL to navigate via a browser to the webpage you created and transferred.
Sample URL: http://hccwebdev.net/~sstewart/helloworld.index.html
End of Directory Structure Chapter
